Simple GP Regression
Gaussian processes are a powerful tool for nonlinear regression models.
Assume that we have predictor variables $\mathbf{X} = \{\mathbf{x_i}\}_{i=1}^N \in \mathbb{R}^d$ and response variables $\mathbf{y}=\{y_i \in \mathbb{R}\}_{i=1}^N$.
The response variables $\mathbf{y}$ are assumed to dependent on the predictors $\mathbf{X}$,
where $f$ is a mapping function. Treating $f$ as a random function, we assume that the distribution over $f$ is a Gaussian process,
where $m(\cdot)$ and $k(\cdot,\cdot)$ are the mean and kernel functions respectively.
1D regression example
We start by simulating some data
using GaussianProcesses
using Random
Random.seed!(20140430)
# Training data
n=10; #number of training points
x = 2π * rand(n); #predictors
y = sin.(x) + 0.05*randn(n); #regressorsThe first step in modelling with Gaussian Processes is to choose mean functions and kernels which describe the process.
Note that all hyperparameters for the mean and kernel functions and $\sigma$ are given on the log scale. This is true for all strictly positive hyperparameters. Gaussian Processes are represented by objects of type 'GP' and constructed from observation data, a mean function and kernel, and optionally the amount of observation noise.
#Select mean and covariance function
mZero = MeanZero() #Zero mean function
kern = SE(0.0,0.0) #Sqaured exponential kernel (note that hyperparameters are on the log scale)
logObsNoise = -1.0 # log standard deviation of observation noise (this is optional)
gp = GP(x,y,mZero,kern,logObsNoise) #Fit the GPGP Exact object:
Dim = 1
Number of observations = 10
Mean function:
Type: MeanZero, Params: Float64[]
Kernel:
Type: SEIso{Float64}, Params: [0.0, 0.0]
Input observations =
[4.85461 5.17653 … 1.99412 3.45676]
Output observations = [-0.967293, -1.00705, -1.0904, 0.881121, -0.333213, -0.976965, 0.915934, 0.736218, 0.950849, -0.306432]
Variance of observation noise = 0.1353352832366127
Marginal Log-Likelihood = -6.335Once we've fit the GP function to the data, we can calculate the predicted mean and variance of the function at unobserved points $\{\mathbf{x}^\ast,y^\ast\}$, conditional on the observed data $\mathcal{D}=\{\mathbf{y},\mathbf{X}\}$. This is done with the predict_y function.
The predict_y function returns the mean vector $\mu(\mathbf{x}^\ast)$ and covariance matrix (variance vector if full_cov=false) $\Sigma(\mathbf{x}^\ast,\mathbf{x}^{\ast^\top})$ of the predictive distribution,
where
Note you can use the predict_f function to predict the latent function $\mathbf{f}^\ast$.
μ, σ² = predict_y(gp,range(0,stop=2π,length=100));([0.357625, 0.384852, 0.412943, 0.441807, 0.471344, 0.501442, 0.53198, 0.562826, 0.593838, 0.624867 … -0.669223, -0.63363, -0.597926, -0.562345, -0.527104, -0.492406, -0.458434, -0.425355, -0.393315, -0.362442], [0.603651, 0.557693, 0.512299, 0.468128, 0.425831, 0.386031, 0.349295, 0.316113, 0.286872, 0.261843 … 0.434056, 0.473396, 0.514594, 0.557168, 0.600593, 0.644326, 0.68782, 0.730548, 0.772021, 0.811799])Plotting GPs is straightforward and utilises the recipes approach to plotting from the Plots.jl package. More information about plotting GPs and the available functionality can be found in this Plotting with GaussianProcesses.jl.
The default plot function plot(gp) outputs the predicted mean and variance of the function (i.e. uses predict_f in the background), with the uncertainty in the function represented by a confidence ribbon (set to 95% by default). All optional plotting arguments are given after ;.
using Plots #Load Plots.jl package
plot(gp; xlabel="x", ylabel="y", title="Gaussian process", legend=false, fmt=:png) # Plot the GP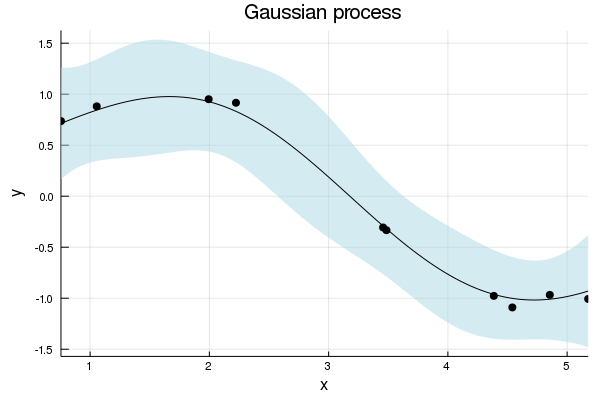
The hyperparameters are optimized using the Optim.jl package. This offers users a range of optimization algorithms which can be applied to estimate the hyperparameters using type II maximum likelihood estimation. Gradients are available for all mean and kernel functions used in the package and therefore it is recommended that the user utilizes gradient based optimization techniques. As a default, the optimize! function uses the L-BFGS solver, however, alternative solvers can be applied.
using Optim
optimize!(gp; method=ConjugateGradient()) # Optimise the hyperparametersResults of Optimization Algorithm
* Algorithm: Conjugate Gradient
* Starting Point: [-1.0,0.0,0.0]
* Minimizer: [-2.992856448832551,0.4636861230870647, ...]
* Minimum: -3.275745e+00
* Iterations: 27
* Convergence: false
* |x - x'| ≤ 0.0e+00: false
|x - x'| = 4.62e-09
* |f(x) - f(x')| ≤ 0.0e+00 |f(x)|: false
|f(x) - f(x')| = -4.12e-14 |f(x)|
* |g(x)| ≤ 1.0e-08: false
|g(x)| = 5.69e-08
* Stopped by an increasing objective: true
* Reached Maximum Number of Iterations: false
* Objective Calls: 66
* Gradient Calls: 41plot(gp; legend=false, fmt=:png) #Plot the GP after the hyperparameters have been optimised 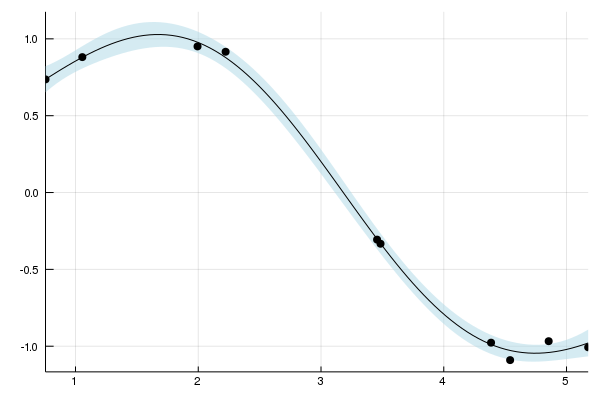
By default all hyperparameters or optimized. But the function optimize! allows also to force hyperparameters to remain constant or optimize them in a box.
optimize!(gp; kern = false) # Don't optimize kernel hyperparameters
optimize!(gp; kernbounds = [[-1, -1], [1, 1]]) # Optimize the kernel parameters in a box with lower bounds [-1, -1] and upper bounds [1, 1]Results of Optimization Algorithm
* Algorithm: Fminbox with L-BFGS
* Starting Point: [-2.992856448832551,0.4636861230870647, ...]
* Minimizer: [-2.992856448832551,0.4636861230870647, ...]
* Minimum: -3.275745e+00
* Iterations: 1
* Convergence: true
* |x - x'| ≤ 0.0e+00: true
|x - x'| = 0.00e+00
* |f(x) - f(x')| ≤ 0.0e+00 |f(x)|: true
|f(x) - f(x')| = 0.00e+00 |f(x)|
* |g(x)| ≤ 1.0e-08: false
|g(x)| = 6.32e-08
* Stopped by an increasing objective: true
* Reached Maximum Number of Iterations: false
* Objective Calls: 3
* Gradient Calls: 3MCMC, specifically a Hamiltonian Monte Carlo in this instance, can be run on the GPE hyperparameters through the mcmc function. Priors for hyperparameters of the mean and kernel parameters can be set through the set_priors! function. The log noise parameter of the GPE is a Uniform(0,1) distribution and currently can't be changed.
using Distributions
set_priors!(kern, [Normal(), Normal()]) # Uniform(0,1) distribution assumed by default if priors not specified
chain = mcmc(gp)
plot(chain', label=["Noise", "SE log length", "SE log scale"]; fmt=:png)Number of iterations = 1000, Thinning = 1, Burn-in = 1
Step size = 0.100000, Average number of leapfrog steps = 9.786000
Number of function calls: 9787
Acceptance rate: 0.959000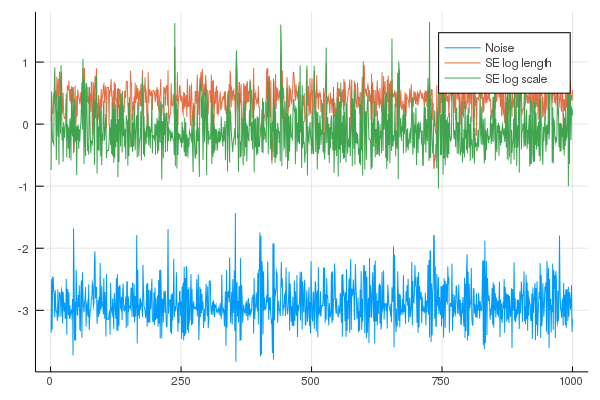
There is additional support for inference to be done in a fully Bayesian fashion through the use of an elliptical slice sampler. While a HMC sampler can often be shown to be highly efficient, the sampler's efficiency can be highly dependent upon good initial choice of the sampler's hyperparameters. Conversely, ESS has no free parameters and is designed to be highly efficient in tightly correlated Gaussian posteriors: a geometry commonly found in Gaussian process models.
Note currently, inference via an ESS is only supported when the likelihood is Gaussian.
For advice on how to fit Gaussian processes with non-Gaussian data, see our documentation on Poisson regression or classification.
mhmc = mean(chain, dims=2)
mess = mean(ess_chain, dims=2)
3×1 Array{Float64,2}:
-2.444901016768212
0.3721835201083439
-0.10584635335452222for (a, b) in zip(mhmc, mess)
eq = abs(a-b)
idx = max(abs(a), abs(b))
return eq < idx/5
endtruemZero = MeanZero() #Zero mean function
kern = SE(0.0,0.0) #Sqaured exponential kernel (note that hyperparameters are on the log scale)
logObsNoise = -1.0 # log standard deviation of observation noise (this is optional)
gpess = GP(x, y, mZero, kern, ) #Fit the GP
set_priors!(kern, [Normal(), Normal()]) # Uniform(0,1) distribution assumed by default if priors not specified
set_priors!(gpess.logNoise, [Distributions.Normal(-1.0, 1.0)])
ess_chain = ess(gpess)
plot(chain', label=["Noise", "SE log length", "SE log scale"]; fmt=:png)Number of iterations = 1000, Thinning = 1, Burn-in = 1
Number of function calls: 6115
Acceptance rate: 0.195503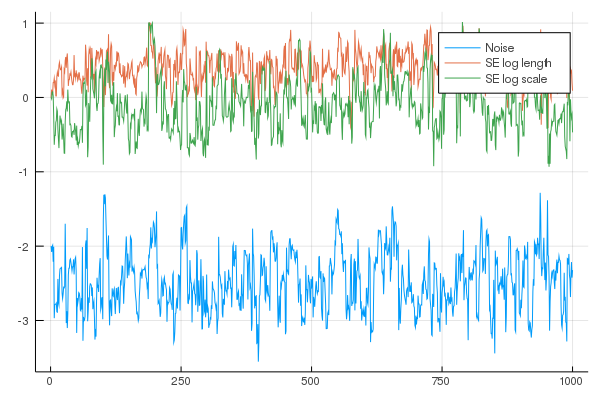
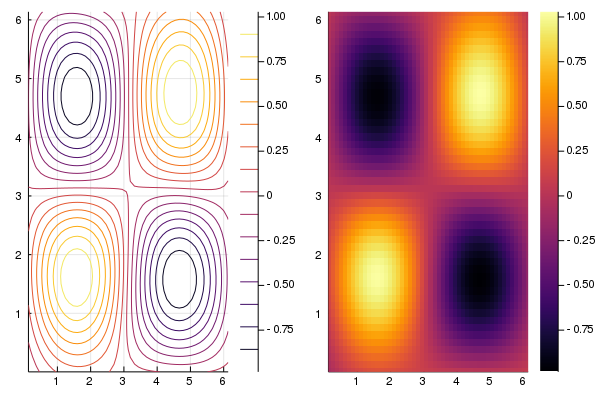
Multi-dimensional regression
The regression example above can be easily extended to higher dimensions. For the purpose of visualisation, and without loss of generality, we consider a 2 dimensional regression example.
#Training data
d, n = 2, 50; #Dimension and number of observations
x = 2π * rand(d, n); #Predictors
y = vec(sin.(x[1,:]).*sin.(x[2,:])) + 0.05*rand(n); #ResponsesFor problems of dimension>1 we can use isotropic (Iso) kernels or automatic relevance determination (ARD) kernels. For Iso kernels, the length scale parameter $\ell$ is the same for all dimensions. For ARD kernels, each dimension has different length scale parameter.
The Iso and ARD kernels are implemented automatically by replacing the single length scale parameter with a vector of parameters. For example, below we use the Matern 5/2 ARD kernel, if we wanted to use the Iso alternative then we would set the kernel as kern=Mat(5/2,0.0,0.0).
In this example we use a composite kernel represented as the sum of a Matern 5/2 ARD kernel and a Squared Exponential isotropic kernel. This is easily implemented using the + symbol, or in the case of a product kernel, using the * symbol (i.e. kern = Mat(5/2,[0.0,0.0],0.0) * SE(0.0,0.0)).
mZero = MeanZero() # Zero mean function
kern = Matern(5/2,[0.0,0.0],0.0) + SE(0.0,0.0) # Sum kernel with Matern 5/2 ARD kernel
# with parameters [log(ℓ₁), log(ℓ₂)] = [0,0] and log(σ) = 0
# and Squared Exponential Iso kernel with
# parameters log(ℓ) = 0 and log(σ) = 0Type: SumKernel{Mat52Ard{Float64},SEIso{Float64}}
Type: Mat52Ard{Float64}, Params: [-0.0, -0.0, 0.0] Type: SEIso{Float64}, Params: [0.0, 0.0]Fit the Gaussian process to the data using the prespecfied mean and covariance functions.
gp = GP(x,y,mZero,kern,-2.0) # Fit the GPGP Exact object:
Dim = 2
Number of observations = 50
Mean function:
Type: MeanZero, Params: Float64[]
Kernel:
Type: SumKernel{Mat52Ard{Float64},SEIso{Float64}}
Type: Mat52Ard{Float64}, Params: [-0.0, -0.0, 0.0] Type: SEIso{Float64}, Params: [0.0, 0.0]
Input observations =
[3.05977 4.74752 … 2.82127 5.38224; 2.02102 4.27258 … 6.13114 1.56497]
Output observations = [0.08509, 0.924505, 0.275745, -0.448035, -0.784758, -0.316803, -0.823483, -0.886726, 0.0059149, 0.414951 … -0.413905, -0.347505, 0.46108, -0.204102, -0.538689, 0.554203, -0.874479, -0.0506017, -0.0215167, -0.745944]
Variance of observation noise = 0.01831563888873418
Marginal Log-Likelihood = -29.547Using the Optim package we have the option to choose from a range of optimize functions including conjugate gradients. It is also possible to fix the hyperparameters in either the mean function, kernel function or observation noise, by settting them to false in optimize! (e.g. optimize!(...,domean=false)).
optimize!(gp) # Optimize the hyperparametersResults of Optimization Algorithm
* Algorithm: L-BFGS
* Starting Point: [-2.0,-0.0,-0.0,0.0,0.0,0.0]
* Minimizer: [-4.277211995773057,5.536664077544042, ...]
* Minimum: -5.023830e+01
* Iterations: 34
* Convergence: false
* |x - x'| ≤ 0.0e+00: false
|x - x'| = 4.74e-02
* |f(x) - f(x')| ≤ 0.0e+00 |f(x)|: false
|f(x) - f(x')| = -1.36e-14 |f(x)|
* |g(x)| ≤ 1.0e-08: false
|g(x)| = 1.87e-05
* Stopped by an increasing objective: true
* Reached Maximum Number of Iterations: false
* Objective Calls: 115
* Gradient Calls: 115A range of plotting options are availbe through the Plots.jl package.
plot(contour(gp) ,heatmap(gp); fmt=:png)